(1) Informação redundante de sinal de vídeo
Tomando o formato de componente YUV de gravação de vídeo digital como exemplo, YUV representa o brilho e dois sinais de diferença de cor, respectivamente. Por exemplo, para o sistema Pal TV existente, a frequência de amostragem do sinal de luminância é de 13.5 MHz; a banda de frequência do sinal de croma é geralmente metade ou menos do sinal de brilho, que é de 6.75 MHz ou 3.375 MHz. Tomando a frequência de amostragem de 4: 2: 2 como exemplo, o sinal Y adota 13.5 mhz, o sinal de croma U e V são amostrados por 6.75 mhz e o sinal de amostragem é quantizado por 8 bits, então a taxa de código do vídeo digital pode ser calculada do seguinte modo:
13.5 * 8 + 6.75 * 8 + 6.75 * 8 = 216Mbit / s
Se uma grande quantidade de dados for armazenada ou transmitida diretamente, será difícil usar a tecnologia de compressão para reduzir a taxa de bits. O sinal de vídeo digital pode ser comprimido de acordo com duas condições básicas:
L. redundância de dados. Por exemplo, redundância espacial, redundância de tempo, redundância de estrutura, redundância de entropia de informação, etc., ou seja, existe uma forte correlação entre os pixels da imagem. Eliminar essas redundâncias não leva à perda de informações e é uma compactação sem perdas.
L. redundância visual. Algumas características dos olhos humanos, como limiar de discriminação de brilho, limiar visual, são diferentes em sensibilidade ao brilho e croma, o que torna impossível introduzir erros apropriados na codificação e não serão detectados. As características visuais dos olhos humanos podem ser usadas para trocar por compressão de dados com certa distorção objetiva. Essa compressão é com perdas.
A compressão do sinal de vídeo digital é baseada nas duas condições acima, o que torna os dados de vídeo altamente comprimidos, o que é propício para transmissão e armazenamento. Os métodos comuns de compressão de vídeo digital são codificação mista, que combina codificação de transformação, estimativa de movimento e compensação de movimento, e codificação de entropia para compactar a codificação. Normalmente, a codificação de transformação é usada para eliminar a redundância intraquadro da imagem, e estimativa de movimento e compensação de movimento são usadas para remover a redundância intraquadro da imagem e a codificação de entropia é usada para melhorar ainda mais a eficiência de compressão. Os três métodos de codificação de compressão a seguir são apresentados resumidamente.
(a) Método de codificação de compressão
(b) Transformar codificação
A função da codificação de transformação é transformar o sinal de imagem descrito no domínio do espaço para o domínio da frequência e, em seguida, codificar os coeficientes transformados. De um modo geral, a imagem tem forte correlação no espaço, e a transformação para o domínio da frequência pode realizar decorrelação e concentração de energia. A transformação ortogonal comum inclui transformada discreta de Fourier, transformada discreta de cosseno e assim por diante. A transformada discreta de cosseno é amplamente usada na compressão de vídeo digital.
A transformação discreta do cosseno é conhecida como transformação DCT. Ele pode transformar o bloco de imagem de L * l do domínio do espaço para o domínio da frequência. Portanto, no processo de compactação e codificação de imagem com base em DCT, a imagem precisa ser dividida em blocos de imagem não sobrepostos. Suponha que o tamanho de uma imagem seja 1280 * 720, ela é dividida em 160 * 90 blocos de imagem com tamanho 8 * 8 sem sobreposição na forma de grade. Então a transformação DCT pode ser executada para cada bloco de imagem.
Depois que o bloco é dividido, cada bloco de imagem de 8 * 8 pontos é enviado para o codificador DCT e o bloco de imagem de 8 * 8 é transformado do domínio espacial para o domínio da frequência. A figura abaixo mostra um exemplo de um bloco de imagem de 8 * 8 em que o número representa o valor de brilho de cada pixel. Pode-se observar na figura que os valores de brilho de cada pixel neste bloco de imagem são relativamente uniformes, principalmente o valor de brilho dos pixels adjacentes não é muito grande, o que indica que o sinal da imagem possui forte correlação.
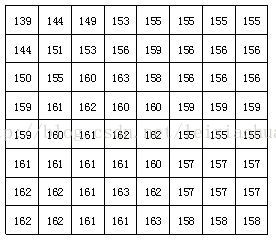
Um bloco de imagem real de 8 * 8
A figura a seguir mostra os resultados da transformação DCT do bloco de imagem na figura acima. Pode-se ver na figura que após a transformação DCT, o coeficiente de baixa frequência no canto superior esquerdo concentra muita energia, enquanto a energia no coeficiente de alta frequência no canto inferior direito é muito pequena.
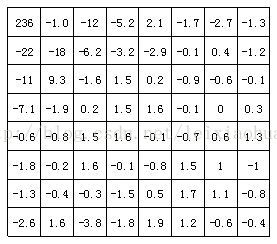
Os coeficientes do bloco de imagem após a transformação DCT
O sinal precisa ser quantificado após a transformação DCT. Como os olhos humanos são sensíveis às características de baixa frequência das imagens, como o brilho geral dos objetos, e não aos detalhes de alta frequência da imagem, portanto, no processo de transmissão, as informações de alta frequência podem ser transmitidas menos ou não, apenas a parte de baixa frequência. O processo de quantização reduz a transmissão de informações ao quantificar os coeficientes da região de baixa frequência e quantização grosseira dos coeficientes da região de alta frequência, o que remove a informação de alta frequência que não é sensível ao olho humano. Portanto, a quantização é um processo de compressão com perdas e a principal razão para os danos à qualidade na codificação de compressão de vídeo.
O processo de quantificação pode ser expresso pela seguinte fórmula:

Entre eles, FQ (U, V) representa o coeficiente DCT após a quantização; f (U, V) representa o coeficiente DCT antes da quantização; Q (U, V) representa a matriz de ponderação de quantização; q é a etapa de quantização; round refere-se à consolidação e o valor a ser produzido é considerado o valor inteiro mais próximo.
Selecione o coeficiente de quantização razoavelmente e o resultado após quantizar o bloco de imagem transformado é mostrado na figura.

Coeficiente DCT após quantificação
A maioria dos coeficientes DCT são alterados para 0 após a quantização, enquanto apenas alguns coeficientes são valores diferentes de zero. Neste momento, apenas esses valores diferentes de zero precisam ser compactados e codificados.
(b) Codificação de entropia
A codificação de entropia é nomeada porque o comprimento médio do código após a codificação é próximo ao valor de entropia da fonte. A codificação de entropia é implementada por VLC (codificação de comprimento variável). O princípio básico é dar código curto ao símbolo com alta probabilidade na fonte e dar código longo ao símbolo com pequena probabilidade de ocorrência, de modo a obter estatisticamente o menor comprimento de código médio. A codificação de comprimento variável geralmente inclui código Hoffman, código aritmético, código de execução, etc. A codificação de comprimento de execução é um método de compressão muito simples, sua eficiência de compressão não é alta, mas a velocidade de codificação e decodificação é rápida e ainda é amplamente utilizada, especialmente após a transformação da codificação, usando a codificação run-length, tem um bom efeito.
Primeiro, o coeficiente AC imediatamente após o coeficiente DC de saída do quantizador deve ser varrido no tipo Z (como mostrado na linha de seta). O Z-scan transforma o coeficiente de quantização bidimensional em uma sequência unidimensional e, em seguida, continua a codificação do comprimento de execução. Finalmente, outro código de comprimento variável é usado para codificar os dados após a codificação de execução, como a codificação de Hoffman. Por meio desse tipo de codificação de comprimento variável, a eficiência da codificação é ainda melhorada.
(c) Estimativa de movimento e compensação de movimento
A estimativa de movimento e a compensação de movimento são métodos eficazes para eliminar a correlação da direção do tempo das sequências de imagens. Os métodos de transformação DCT, quantização e codificação de entropia descritos acima são baseados em uma imagem de quadro. Por meio desses métodos, a correlação espacial entre os pixels da imagem pode ser eliminada. Na verdade, além da correlação espacial, o sinal da imagem possui correlação temporal. Por exemplo, para vídeo digital com fundo estático como transmissão de notícias e pequeno movimento do corpo principal da imagem, a diferença entre cada imagem é muito pequena e a correlação entre as imagens é muito grande. Nesse caso, não precisamos codificar cada imagem de quadro separadamente, mas podemos codificar apenas as partes alteradas de quadros de vídeo adjacentes, de modo a reduzir ainda mais a quantidade de dados. Este trabalho é realizado por estimativa de movimento e compensação de movimento.
A tecnologia de estimativa de movimento geralmente divide a imagem de entrada atual em vários pequenos sub-blocos de imagem que não se sobrepõem, por exemplo, o tamanho de uma imagem de quadro é 1280 * 720. Em primeiro lugar, é dividido em 40 * 45 blocos de imagem com 16 * 16 tamanho que não se sobrepõem na forma de grade, e então, no âmbito de uma janela de busca da imagem anterior ou da última imagem, encontre um bloco para cada bloco de imagem para encontrar um bloco de imagem dentro do escopo de um janela de pesquisa O bloco de imagem mais semelhante. O processo de pesquisa é denominado estimativa de movimento. Calculando a informação de posição entre o bloco de imagem mais semelhante e o bloco de imagem, um vetor de movimento pode ser obtido. Desta forma, o bloco de imagem atual pode ser subtraído do bloco de imagem mais semelhante apontado pelo vetor de movimento da imagem de referência e um bloco de imagem residual pode ser obtido. Como cada valor de pixel no bloco de imagem residual é muito pequeno, uma taxa de compressão mais alta pode ser obtida na codificação de compressão. Este processo de subtração é denominado compensação de movimento.
Como a imagem de referência é necessária para ser usada para estimativa de movimento e compensação de movimento no processo de codificação, é muito importante selecionar a imagem de referência. Geralmente, o codificador divide cada entrada de imagem de quadro em três tipos diferentes de acordo com as diferentes imagens de referência: quadro I (intra), quadro B (previsão de orientação) e quadro P (previsão). Conforme mostrado na figura.
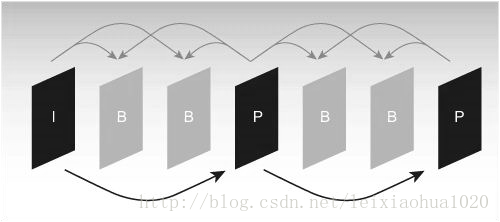
Sequência de estrutura de quadro I, B, P típica
Conforme mostrado na figura, o quadro I usa apenas os dados do quadro para codificação e não precisa de estimativa de movimento e compensação de movimento durante o processo de codificação. Obviamente, como o quadro I não elimina a correlação da direção do tempo, a taxa de compressão é relativamente baixa. No processo de codificação, o quadro P usa um quadro I frontal ou quadro P como imagem de referência para a compensação de movimento; na verdade, ele codifica a diferença entre a imagem atual e a imagem de referência. O modo de codificação do quadro B é semelhante ao quadro P, a única diferença é que ele precisa usar um quadro I frontal ou quadro P e um quadro I ou P posterior para prever durante o processo de codificação. Assim, cada codificação de quadro P precisa usar uma imagem de quadro como imagem de referência, enquanto o quadro B precisa de dois quadros como referência. Em contraste, o quadro B tem uma taxa de compressão mais alta do que o quadro P.
(d) Codificação mista
O artigo apresenta vários métodos importantes de compressão e codificação de vídeo. Na aplicação prática, esses métodos não são separados e geralmente são combinados para obter o melhor efeito de compressão. A figura a seguir mostra o modelo de codificação híbrida (ou seja, codificação de transformação + estimativa de movimento e compensação de movimento + codificação de entropia). O modelo é amplamente utilizado em MPEG1, MPEG2, H.264 e outros padrões. Pela figura, podemos ver que a imagem de entrada atual deve ser dividida em blocos primeiro, o bloco da imagem obtido pelo bloco deve ser subtraído do imagem prevista após compensação de movimento para obter a imagem de diferença x, e então a transformação e quantização DCT são realizadas para o bloco de imagem de diferença. Os dados de saída quantizados têm dois lugares diferentes: um é enviá-los para o codificador de entropia para codificação, e o fluxo de código codificado é enviado para um cache Salve no dispositivo e aguarde a transmissão. Outra aplicação é contra-quantificar e reverter a mudança para o sinal x ', que adiciona a saída do bloco de imagem com compensação de movimento para obter um novo sinal de imagem de previsão e envia um novo bloco de imagem de previsão para a memória de quadros.



|
|
|
|
Como distante (long) a tampa do transmissor?
A faixa de transmissão depende de muitos fatores. A distância real baseia-se na altura da antena de instalar, o ganho da antena, usando ambiente como a construção e outras obstruções, a sensibilidade do receptor, a antena do receptor. Instalação de antena mais alta e usando no campo, a distância vai muito mais longe.
EXEMPLO 5W FM Transmitter usar na cidade e cidade natal:
Eu tenho um uso do cliente 5W transmissor FM EUA com antena GP em sua cidade natal, e ele testá-lo com um carro, cobrir 10km (6.21mile).
I testar o transmissor FM 5W com antena GP na minha cidade natal, que cobrem cerca de 2km (1.24mile).
I testar o transmissor FM 5W com antena GP na cidade de Guangzhou, que abrangem cerca de única 300meter (984ft).
Abaixo estão o intervalo aproximado de diferentes transmissores de energia FM. (O intervalo é de diâmetro)
0.1W ~ 5W Transmissor FM: 100M ~ 1KM
5W ~ 15W FM Ttransmitter: 1KM ~ 3KM
15W ~ 80W Transmissor FM: 3KM ~ 10KM
80W ~ 500W Transmissor FM: 10KM ~ 30KM
500W ~ 1000W Transmissor FM: 30KM ~ 50KM
1KW ~ 2KW Transmissor FM: 50KM ~ 100KM
2KW ~ 5KW Transmissor FM: 100KM ~ 150KM
5KW ~ 10KW Transmissor FM: 150KM ~ 200KM
Como contactar-nos para o transmissor?
Ligue-me + 8618078869184 OR
Me mande um e-mail [email protegido]
1.How longe você quer cobrir de diâmetro?
2.How altura de vocês torre?
3.Where você é?
E vamos dar-lhe conselhos mais profissional.
Sobre Nós
A FMUSER.ORG é uma empresa de integração de sistemas com foco em transmissão de RF sem fio / equipamento de áudio de vídeo de estúdio / streaming e processamento de dados. Fornecemos desde consultoria e consultoria até integração de rack a instalação, comissionamento e treinamento.
Oferecemos Transmissor FM, Transmissor de TV Analógico, Transmissor de TV Digital, Transmissor UHF VHF, Antenas, Conectores Coaxiais, STL, Processamento On Air, Produtos Broadcast para Estúdio, Monitoramento de Sinais RF, Codificadores RDS, Processadores de Áudio e Unidades de Controle Remoto, Produtos de IPTV, codificador / decodificador de vídeo / áudio, projetados para atender às necessidades tanto de grandes redes de transmissão internacionais quanto de pequenas estações privadas.
Nossa solução possui Estação de Rádio FM / Estação de TV Analógica / Estação de TV Digital / Equipamento de Estúdio de Áudio / Vídeo / Link de Transmissor de Estúdio / Sistema de Telemetria de Transmissor / Sistema de TV de Hotel / Transmissão ao Vivo de IPTV / Transmissão ao Vivo de Transmissão / Conferência de Vídeo / Sistema de Transmissão de CATV.
Estamos usando produtos de tecnologia avançada para todos os sistemas, porque sabemos que a alta confiabilidade e o alto desempenho são tão importantes para o sistema e a solução. Ao mesmo tempo, também temos que garantir que nosso sistema de produtos tenha um preço muito razoável.
Temos clientes de radiodifusores públicos e comerciais, operadoras de telecomunicações e autoridades reguladoras, além de oferecer soluções e produtos para centenas de pequenas emissoras locais e comunitárias.
A FMUSER.ORG exporta há mais de 15 anos e tem clientes em todo o mundo. Com 13 anos de experiência neste campo, temos uma equipe profissional para resolver todos os tipos de problemas dos clientes. Nós nos dedicamos a fornecer preços extremamente razoáveis para produtos e serviços profissionais. Email de contato : [email protegido]
Nossa fábrica

Nós temos modernização da fábrica. Você está convidado a visitar nossa fábrica quando você vir para a China.

Actualmente, já existem clientes 1095 em todo o mundo visitaram nosso escritório Guangzhou Tianhe. Se você vir para a China, você está convidado a visitar-nos.
na Feira

Esta é a nossa participação em 2012 Global Sources Hong Kong Fair Eletrônica . Clientes de todo o mundo finalmente ter a chance de ficar juntos.
Onde está Fmuser?
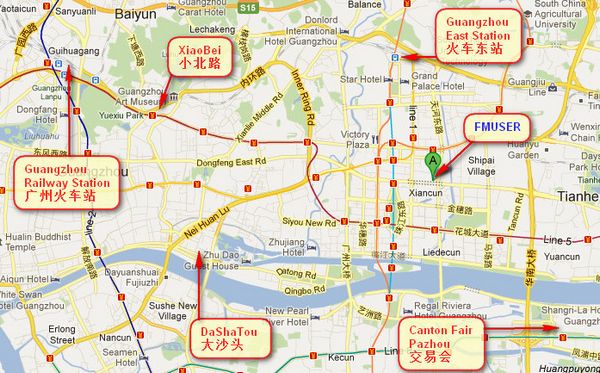
Você pode pesquisar esses números " 23.127460034623816,113.33224654197693 "no google map, então você pode encontrar nosso escritório fmuser.
escritório FMUSER Guangzhou está em Tianhe District, que é a centro do cantão . Muito perto ao Feira de Cantão , Estação Ferroviária Guangzhou, estrada Xiaobei e dashatou , só precisa 10 minutos se tomar TÁXI . Bem-vindos amigos de todo o mundo para visitar e negociar.
Contato: Céu azul
Celular: + 8618078869184
WhatsApp: + 8618078869184
WeChat: + 8618078869184
E-mail [email protegido]
QQ: 727926717
Skype: sky198710021
Endereço: No.305 quarto Huilan Edifício No.273 Huanpu Estrada Guangzhou China Zip: 510620
|
|
|
|
Inglês: Aceitamos todos os pagamentos, como PayPal, cartão de crédito, Western Union, Alipay, Money Bookers, T / T, LC, DP, DA, OA, Payoneer, se você tiver alguma dúvida, entre em contato comigo [email protegido] ou WhatsApp + 8618078869184
-
PayPal.  www.paypal.com www.paypal.com
Recomendamos que você use Paypal para comprar nossos produtos, o Paypal é uma forma segura de comprar na internet.
Cada da nossa lista de itens de página de fundo na parte superior tem um logotipo paypal para pagar.
Cartão de crédito.Se você não tem paypal, mas você tem cartão de crédito, você também pode clicar no botão amarelo PayPal para pagar com seu cartão de crédito.
-------------------------------------------------- -------------------
Mas se você não tiver um cartão de crédito e não tem uma conta paypal ou de difícil tem um accout PayPal, você pode usar o seguinte:
Western Union.  www.westernunion.com www.westernunion.com
Pagamento por Western Union para mim:
Nome próprio / nome próprio: Yingfeng
Sobrenome / sobrenome / sobrenome: Zhang
Nome completo: Yingfeng Zhang
País: China
Cidade: Guangzhou
|
-------------------------------------------------- -------------------
T / T. Pagar por T / T (transferência bancária / transferência telegráfica / Transferência Bancária)
Primeiras INFORMAÇÕES BANCÁRIAS (CONTA DA EMPRESA):
SWIFT BIC: BKCHHKHHXXX
Nome do banco: BANK OF CHINA (HONG KONG) LIMITADA, HONG KONG
Endereço do Banco: BANK OF CHINA TOWER, 1 GARDEN ROAD, CENTRAL, HONG KONG
CÓDIGO BANCÁRIO: 012
Nome da conta: FMUSER INTERNATIONAL GROUP LIMITED
Conta NO. : 012-676-2-007855-0
-------------------------------------------------- -------------------
SEGUNDA INFORMAÇÃO BANCÁRIA (CONTA DA EMPRESA):
Beneficiário: Fmuser International Group Inc
Número da conta: 44050158090900000337
Banco do beneficiário: Sucursal do China Construction Bank em Guangdong
Código SWIFT: PCBCCNBJGDX
Endereço: NO.553 Tianhe Road, Guangzhou, Guangdong, distrito de Tianhe, China
** Nota: Quando você transferir dinheiro para nossa conta bancária, NÃO escreva nada na área de comentários, caso contrário, não poderemos receber o pagamento devido à política governamental sobre negócios de comércio internacional.
|
|
|
|
* Será enviada em 1 2-dia de trabalho quando o pagamento clara.
* Nós vamos enviá-lo para seu endereço de paypal. Se você quiser mudar de endereço, por favor, envie seu endereço correto e número de telefone para o meu e-mail [email protegido]
* Se os pacotes está abaixo 2kg, que serão enviados via correio aéreo, vai demorar cerca de 15-25days para sua mão.
Se o pacote é mais do que 2kg, nós enviamos via EMS, DHL, UPS, Fedex entrega rápida expressa, vai demorar cerca de 7 ~ 15days para sua mão.
Se o pacote de mais de 100kg, iremos enviar via DHL ou frete aéreo. Isso levará cerca de 3 ~ 7days para sua mão.
Todos os pacotes são a forma China Guangzhou.
* O pacote será enviado como um "presente" e descontar o menos possível, o comprador não precisa pagar por "TAX".
* Depois de navio, nós lhe enviaremos um e-mail e dar-lhe o número de rastreamento.
|
|
|
Para garantia.
Entre em contato conosco --- >> Devolva o item para nós --- >> Receba e envie outra substituição.
Nome: Liu Xiaoxia
Endereço: 305Fang HuiLanGe HuangPuDaDaoXi 273Hao TianHeQu Guangzhou China.
CEP: 510620
Telefone: + 8618078869184
Por favor, retorne a este endereço e escrever seu paypal endereço, nome, problema na nota: |
|













